Currently, ALOE provides tag clouds in two different contexts: On the welcome page we display a cloud with the most popular tags in the system, and on the detail page of a resource, we show which tags have been assigned to this resource so far (this is also displayed as a cloud because we follow a bag model for tagging resources). In our tag clouds, we don’t do any clustering based on relations between tags, and we don’t care about smart placement of the tags - although this would surely be interesting. It’s just a matter of time and where to spend your energy  So we only try to map a tag’s frequency to a certain font size. I’ll now explain how we have built the tag clouds until now, and how we will do it in the future. Therefore, let
So we only try to map a tag’s frequency to a certain font size. I’ll now explain how we have built the tag clouds until now, and how we will do it in the future. Therefore, let
- n be the number of different font sizes you want to use,
- f_min the lowest and f_max the highest frequency of a tag in the cloud, and
- f_t the frequency of a given tag t
Until now, we followed a very straightforward approach to generate these tag clouds (I’ll write it down a bit sloppily, but I’m sure you can follow): We choose the 50 most frequently assigned tags, looked at the difference f_max-f_min and divided it by n to have the same frequency range r for each available font size. Then we simply assigned all tags t with f_min <= f_t < f_min +r to the smallest font size, the ones with a frequency f_min + r <= f_t < f_min +2r to the next font size and so on and so on. We knew that this approach isn’t very smart, but good enough for most use cases. And it always worked nice in all ALOE scenarios, so we didn’t put any more effort in it. But then, our colleagues from MACE pointed us to a problem with the tag cloud generated by ALOE. What was the problem? Here’s a screenshot taken from the Social Search page in MACE:
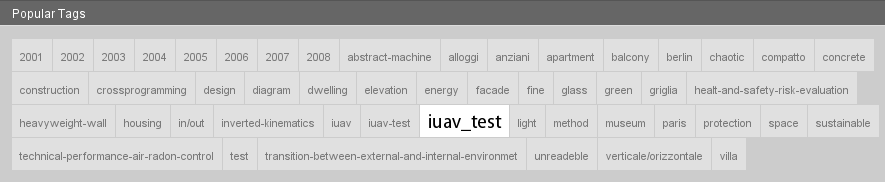
Here is how it looks if displayed with the ALOE front end:

So we have one really big tag - namely “iuav_test” - and all other tags are displayed with the same, smallest font size. The reason for this is simple:The frequencies are not equally distributed within the tags to be displayed, and that’s what we assume when we generate a tag cloud in the way I explained. In fact, we have the following frequencies in this example:
- iuav_test: 176
- glass: 29
- light: 25
- diagram: 16
- unreadeble: 14
- …
- vanderrohe: 4
It is clear what happened: With 5 available font sizes, we have (176-4)/5=34.4 as the frequency range for each font size - so everything except for “iuav_test” is displayed with the smallest font size. So what can we do to deal with such outliers or big skips between frequencies of the tags? We decided that we want to have the following characteristics in our tag clouds:
- It should work like it did before for equally distributed tags, but also for other cases.
- Tags with a similar frequency should be displayed with a similar font size in the cloud.
- A big skip in the frequency distribution should result in a big skip in the font size.
- We still want to use as many font sizes as possible.
After some brainstorming, we decided to implement the following algorithm:
T:=the set with all tags to be displayed
i:=1, r:=(f_max-f_min)/n
while(T is not empty)
T_i:= the set of all tags t in T with f_min <= f_t < f_min +r
T:=T\T_i
i:=i+1
if (T_i is empty)
i:=i+1 /* one font size won’t be used */
f_min:=the lowest frequency of a tag in T
r:=(f_max-f_min)/(n-i)
This is still quite simple, but it does a nice job and fulfills all the demanded criteria. As a default, it still uses the same frequency range for all font sizes. When we find a tag for each range (i.e. font size), the algorithm does exactly the same as the original one. But as soon as we don’t find a tag for a certain range, we do the following things:
- We still skip this range, so that there is a corresponding skip in the visualization.
- We look at the remaining tags that we still have to distribute and look for what’s the lowest frequency of a tag. Then we use this new f_min to calculate a new default range for the remaining tags and font sizes.
- We continue recursively.
And here’s the resulting tag cloud for the above example:

Much better now, I think!